mardi 20 février 2018
The Google Ranking Factor You Can Influence in an Afternoon [Case Study]
Posted by sanfran
What does Google consider “quality content"? And how do you capitalize on a seemingly subjective characteristic to improve your standing in search?
We’ve been trying to figure this out since the Hummingbird algorithm was dropped in our laps in 2013, prioritizing “context” over “keyword usage/frequency.” This meant that Google’s algorithm intended to understand the meaning behind the words on the page, rather than the page’s keywords and metadata alone.
This new sea change meant the algorithm was going to read in between the lines in order to deliver content that matched the true intent of someone searching for a keyword.
Write longer content? Not so fast!
Watching us SEOs respond to Google updates is hilarious. We’re like a floor full of day traders getting news on the latest cryptocurrency.
One of the most prominent theories that made the rounds was that longer content was the key to organic ranking. I’m sure you’ve read plenty of articles on this. We at Brafton, a content marketing agency, latched onto that one for a while as well. We even experienced some mixed success.
However, what we didn’t realize was that when we experienced success, it was because we accidentally stumbled on the true ranking factor.
Longer content alone was not the intent behind Hummingbird.
Content depth
Let’s take a hypothetical scenario.
If you were to search the keyword “search optimization techniques,” you would see a SERP that looks similar to the following:

Nothing too surprising about these results.
However, if you were to go through each of these 10 results and take note of the major topics they discussed, theoretically you would have a list of all the topics being discussed by all of the top ranking sites.
Example:
Position 1 topics discussed: A, C, D, E, F
Position 2 topics discussed: A, B, F
Position 3 topics discussed: C, D, F
Position 4 topics discussed: A, E, F
Once you finished this exercise, you would have a comprehensive list of every topic discussed (A–F), and you would start to see patterns of priority emerge.
In the example above, note “topic F” is discussed in all four pieces of content. One would consider this a cornerstone topic that should be prioritized.
If you were then to write a piece of content that covered each of the topics discussed by every competitor on page one, and emphasized the cornerstone topics appropriately, in theory, you would have the most comprehensive piece of content on that particular topic.
By producing the most comprehensive piece of content available, you would have the highest quality result that will best satisfy the searcher’s intent. More than that, you would have essentially created the ultimate resource center for everything a person would want to know about that topic.
How to identify topics to discuss in a piece of content
At this point, we’re only theoretical. The theory makes logical sense, but does it actually work? And how do we go about scientifically gathering information on topics to discuss in a piece of content?
Finding topics to cover:
- Manually: As discussed previously, you can do it manually. This process is tedious and labor-intensive, but it can be done on a small scale.
- Using SEMrush: SEMrush features an SEO content template that will provide guidance on topic selection for a given keyword.
- Using MarketMuse: MarketMuse was originally built for the very purpose of content depth, with an algorithm that mimics Hummingbird. MM takes a largely unscientific process and makes it scientific. For the purpose of this case study, we used MarketMuse.
The process
Watch the process in action
1. Identify content worth optimizing
We went through a massive list of keywords our blog ranked for. We filtered that list down to keywords that were not ranking number one in SERPs but had strong intent. You can also do this with core landing pages.

Here’s an example: We were ranking in the third position for the keyword “financial content marketing.” While this is a low-volume keyword, we were enthusiastic to own it due to the high commercial intent it comes with.

2. Evaluate your existing piece
Take a subjective look at your piece of content that is ranking for the keyword. Does it SEEM like a comprehensive piece? Could it benefit from updated examples? Could it benefit from better/updated inline embedded media? With a cursory look at our existing content, it was clear that the examples we used were old, as was the branding.
3. Identify topics
As mentioned earlier, you can do this in a few different ways. We used MarketMuse to identify the topics we were doing a good job of covering as well as our topic gaps, topics that competitors were discussing, but we were not. The results were as follows:
Topics we did a good job of covering:
- Content marketing impact on branding
- Impact of using case studies
- Importance of infographics
- Business implications of a content marketing program
- Creating articles for your audience
Topics we did a poor job of covering:
- Marketing to millennials
- How to market to existing clients
- Crafting a content marketing strategy
- Identifying and tracking goals
4. Rewrite the piece
Considering how out-of-date our examples were, and the number of topics we had neglected to discuss, we determined a full rewrite of the piece was warranted. Our writer, Mike O’Neill, was given the topic guidance, ensuring he had a firm understanding of everything that needed to be discussed in order to create a comprehensive article.
5. Update the content
To maintain our link equity, we kept the same URL and simply updated the old content with the new. Then we updated the publish date. The new article looks like this, with updated content depth, modern branding, and inline visuals.
6. Fetch as Google
Rather than wait for Google to reindex the content, I wanted to see the results immediately (and it is indeed immediate).
7. Check your results
Open an incognito window and see your updated position.
Promising results:
We have run more than a dozen experiments and have seen positive results across the board. As demonstrated in the video, these results are usually realized within 60 seconds of reindexing the updated content.
|
Keyword target |
Old Ranking |
New ranking |
|---|---|---|
|
“Financial content marketing” |
3 |
1 |
|
“What is a subdomain” |
16 |
6 |
|
“Best company newsletters” |
32 |
4 |
|
“Staffing marketing” |
7 |
3 |
|
“Content marketing agency” |
16 |
1 |
|
“Google local business cards” |
16 |
5 |
|
“Company blog” |
7 |
4 |
|
“SEO marketing tools” |
9 |
3 |
Of those tests, here’s another example of this process in action for the keyword, “best company newsletters.”
Before:

After

Assumptions:
From these results, we can assume that content depth and breadth of topic coverage matters — a lot. Google’s algorithm seems to have an understanding of the competitive topic landscape for a keyword. In our hypothetical example from before, it would appear the algorithm knows that topics A–F exist for a given keyword and uses that collection of topics as a benchmark for content depth across competitors.
We can also assume Google’s algorithm either a.) responds immediately to updated information, or b.) has a cached snapshot of the competitive content depth landscape for any given keyword. Either of these scenarios is very likely because of the speed at which updated content is re-ranked.
In conclusion, don’t arbitrarily write long content and call it “high quality.” Choose a keyword you want to rank for and create a comprehensive piece of content that fully supports that keyword. There is no guarantee you’ll be granted a top position — domain strength factors play a huge role in rankings — but you’ll certainly improve your odds, as we have seen.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
lundi 19 février 2018
The Biggest Mistake Digital Marketers Ever Made: Claiming to Measure Everything
Posted by willcritchlow
Digital marketing is measurable.
It’s probably the single most common claim everyone hears about digital, and I can’t count the number of times I’ve seen conference speakers talk about it (heck, I’ve even done it myself).
I mean, look at those offline dinosaurs, the argument goes. They all know that half their spend is wasted — they just don’t know which half.
Maybe the joke’s on us digital marketers though, who garnered only 41% of global ad spend even in 2017 after years of strong growth.
Unfortunately, while we were geeking out about attribution models and cross-device tracking, we were accidentally triggering a common human cognitive bias that kept us anchored on small amounts, leaving buckets of money on the table and fundamentally reducing our impact and access to the C-suite.
And what’s worse is that we have convinced ourselves that it’s a critical part of what makes digital marketing great. The simplest way to see this is to realize that, for most of us, I very much doubt that if you removed all our measurement ability we’d reduce our digital marketing investment to nothing.
In truth, of course, we’re nowhere close to measuring all the benefits of most of the things we do. We certainly track the last clicks, and we’re not bad at tracking any clicks on the path to conversion on the same device, but we generally suck at capturing:
- Anything that happens on a different device
- Brand awareness impacts that lead to much later improvements in conversion rate, average order value, or lifetime value
- Benefits of visibility or impressions that aren’t clicked
- Brand affinity generally
The cognitive bias that leads us astray
All of this means that the returns we report on tend to be just the most direct returns. This should be fine — it’s just a floor on the true value (“this activity has generated at least this much value for the brand”) — but the “anchoring” cognitive bias means that it messes with our minds and our clients’ minds. Anchoring is the process whereby we fixate on the first number we hear and subsequently estimate unknowns closer to the anchoring number than we should. Famous experiments have shown that even showing people a totally random number can drag their subsequent estimates up or down.
So even if the true value of our activity was 10x the measured value, we’d be stuck on estimating the true value as very close to the single concrete, exact number we heard along the way.
This tends to result in the measured value being seen as a ceiling on the true value. Other biases like the availability heuristic (which results in us overstating the likelihood of things that are easy to remember) tend to mean that we tend to want to factor in obvious ways that the direct value measurement could be overstating things, and leave to one side all the unmeasured extra value.
The mistake became a really big one because fortunately/unfortunately, the measured return in digital has often been enough to justify at least a reasonable level of the activity. If it hadn’t been (think the vanishingly small number of people who see a billboard and immediately buy a car within the next week when they weren’t otherwise going to do so) we’d have been forced to talk more about the other benefits. But we weren’t. So we lazily talked about the measured value, and about the measurability as a benefit and a differentiator.
The threats of relying on exact measurement
Not only do we leave a whole load of credit (read: cash) on the table, but it also leads to threats to measurability being seen as existential threats to digital marketing activity as a whole. We know that there are growing threats to measuring accurately, including regulatory, technological, and user-behavior shifts:
- GDPR and other privacy regulations are limiting what we are allowed to do (and, as platforms catch up, what we can do)
- Privacy features are being included in more products, added on by savvy consumers, or simply being set to be on by default more often, with even the biggest company in the world touting privacy as a core differentiator
- Users continue to increase the extent to which they research and buy across multiple devices
- Compared to early in Google’s rise, the lack of keyword-level analytics data and the rise of (not provided) means that we have far less visibility into the details than we used to when the narrative of measurability was being written
Now, imagine that the combination of these trends meant that you lost 100% of your analytics and data. Would it mean that your leads stopped? Would you immediately turn your website off? Stop marketing?
I suggest that the answer to all of that is “no.” There's a ton of value to digital marketing beyond the ability to track specific interactions.
We’re obviously not going to see our measurable insights disappear to zero, but for all the reasons I outlined above, it’s worth thinking about all the ways that our activities add value, how that value manifests, and some ways of proving it exists even if you can’t measure it.
How should we talk about value?
There are two pieces to the brand value puzzle:
- Figuring out the value of increasing brand awareness or affinity
- Understanding how our digital activities are changing said awareness or affinity
There's obviously a lot of research into brand valuations generally, and while it’s outside the scope of this piece to think about total brand value, it’s worth noting that some methodologies place as much as 75% of the enterprise value of even some large companies in the value of their brands:

Image source
My colleague Tom Capper has written about a variety of ways to measure changes in brand awareness, which attacks a good chunk of the second challenge. But challenge #1 remains: how do we figure out what it’s worth to carry out some marketing activity that changes brand awareness or affinity?
In a recent post, I discussed different ways of building marketing models and one of the methodologies I described might be useful for this - namely so-called “top-down” modelling which I defined as being about percentages and trends (as opposed to raw numbers and units of production).
The top-down approach
I’ve come up with two possible ways of modelling brand value in a transactional sense:
1. The Sherlock approach
“When you have eliminated the impossible, whatever remains, however improbable, must be the truth."
- Sherlock Holmes
The outline would be to take the total new revenue acquired in a period. Subtract from this any elements that can be attributed to specific acquisition channels; whatever remains must be brand. If this is in any way stable or predictable over multiple periods, you can use it as a baseline value from which to apply the methodologies outlined above for measuring changes in brand awareness and affinity.
2. Aggressive attribution
If you run normal first-touch attribution reports, the limitations of measurement (clearing cookies, multiple devices etc) mean that you will show first-touch revenue that seems somewhat implausible (e.g. email; email surely can’t be a first-touch source — how did they get on your email list in the first place?):
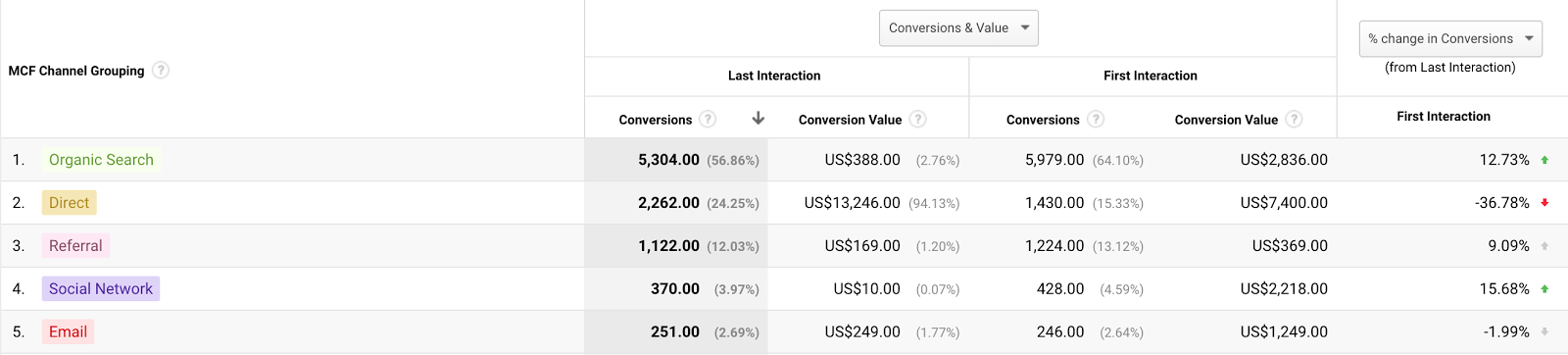
In this screenshot we see that although first-touch dramatically reduces the influence of direct, for instance, it still accounts for more than 15% of new revenue.
The aggressive attribution model takes total revenue and splits it between the acquisition channels (unbranded search, paid social, referral). A first pass on this would simply split it in the relative proportion to the size of each of those channels, effectively normalizing them, though you could build more sophisticated models.
Note that there is no way of perfectly identifying branded/unbranded organic search since (not provided) and so you’ll have to use a proxy like homepage search vs. non-homepage search.
But fundamentally, the argument here would be that any revenue coming from a “first touch” of:
- Branded search
- Direct
- Organic social
...was actually acquired previously via one of the acquisition channels and so we attempt to attribute it to those channels.
Even this under-represents brand value
Both of those methodologies are pretty aggressive — but they might still under-represent brand value. Here are two additional mechanics where brand drives organic search volume in ways I haven’t figured out how to measure yet:
Trusting Amazon to rank
I like reading on the Kindle. If I hear of a book I’d like to read, I’ll often Google the name of the book on its own and trust that Amazon will rank first or second so I can get to the Kindle page to buy it. This is effectively a branded search for Amazon (and if it doesn’t rank, I’ll likely follow up with a [book name amazon] search or head on over to Amazon to search there directly).
But because all I’ve appeared to do is search [book name] on Google and then click through to Amazon, there is nothing to differentiate this from an unbranded search.
Spotting brands you trust in the SERPs
I imagine we all have anecdotal experience of doing this: you do a search and you spot a website you know and trust (or where you have an account) ranking somewhere other than #1 and click on it regardless of position.
One time that I can specifically recall noticing this tendency growing in myself was when I started doing tons more baby-related searches after my first child was born. Up until that point, I had effectively zero brand affinity with anyone in the space, but I quickly grew to rate the content put out by babycentre (babycenter in the US) and I found myself often clicking on their result in position 3 or 4 even when I hadn’t set out to look for them, e.g. in results like this one:

It was fascinating to me to observe this behavior in myself because I had no real interaction with babycentre outside of search, and yet, by consistently ranking well across tons of long-tail queries and providing consistently good content and user experience I came to know and trust them and click on them even when they were outranked. I find this to be a great example because it is entirely self-contained within organic search. They built a brand effect through organic search and reaped the reward in increased organic search.
I have essentially no ideas on how to measure either of these effects. If you have any bright ideas, do let me know in the comments.
Budgets will come under pressure
My belief is that total digital budgets will continue to grow (especially as TV continues to fragment), but I also believe that individual budgets are going to come under scrutiny and pressure making this kind of thinking increasingly important.
We know that there is going to be pressure on referral traffic from Facebook following the recent news feed announcements, but there is also pressure on trust in Google:
- Before the recent news feed changes, slightly misleading stories had implied that Google had lost the top spot as the largest referrer of traffic (whereas in fact this was only briefly true in media)
- The growth of the mobile-first card view and richer and richer SERPs has led to declines in outbound CTR in some areas
- The increasingly black-box nature of Google’s algorithm and an increasing use of ML make the algorithm increasingly impenetrable and mean that we are having to do more testing on individual sites to understand what works
While I believe that the opportunity is large and still growing (see, for example, this slide showing Google growing as a referrer of traffic even as CTR has declined in some areas), it’s clear that the narrative is going to lead to more challenging conversations and budgets under increased scrutiny.
Can you justify your SEO investment?
What do you say when your CMO asks what you’re getting for your SEO investment?
What do you say when she asks whether the organic search opportunity is tapped out?
I’ll probably explore the answers to both these questions more in another post, but suffice it to say that I do a lot of thinking about these kinds of questions.
The first is why we have built our split-testing platform to make organic SEO investments measurable, quantifiable and accountable.
The second is why I think it’s super important to remember the big picture while the media is running around with hair on fire. Media companies saw Facebook overtake Google as a traffic channel (and then are likely seeing that reverse right now), but most of the web has Google as the largest and growing source of traffic and value.
The reality (from clickstream data) is that it's really easy to forget how long the long-tail is and how sparse search features and ads are on the extreme long-tail:
- Only 3–4% of all searches result in a click on an ad, for example. Google's incredible (and still growing) business is based on a small subset of commercial searches
- Google's share of all outbound referral traffic across the web is growing (and Facebook's is shrinking as they increasingly wall off their garden)
The opportunity is for smart brands to capitalize on a growing opportunity while their competitors sink time and money into a social space that is increasingly all about Facebook, and increasingly pay-to-play.
What do you think? Are you having these hard conversations with leadership? How are you measuring your digital brand’s value?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
vendredi 16 février 2018
Using the Cross Domain Rel=Canonical to Maximize the SEO Value of Cross-Posted Content - Whiteboard Friday
Posted by randfish
Same content, different domains? There's a tag for that. Using rel=canonical to tell Google that similar or identical content exists on multiple domains has a number of clever applications. You can cross-post content across several domains that you own, you can benefit from others republishing your own content, rent or purchase content on other sites, and safely use third-party distribution networks like Medium to spread the word. Rand covers all the canonical bases in this not-to-be-missed edition of Whiteboard Friday.
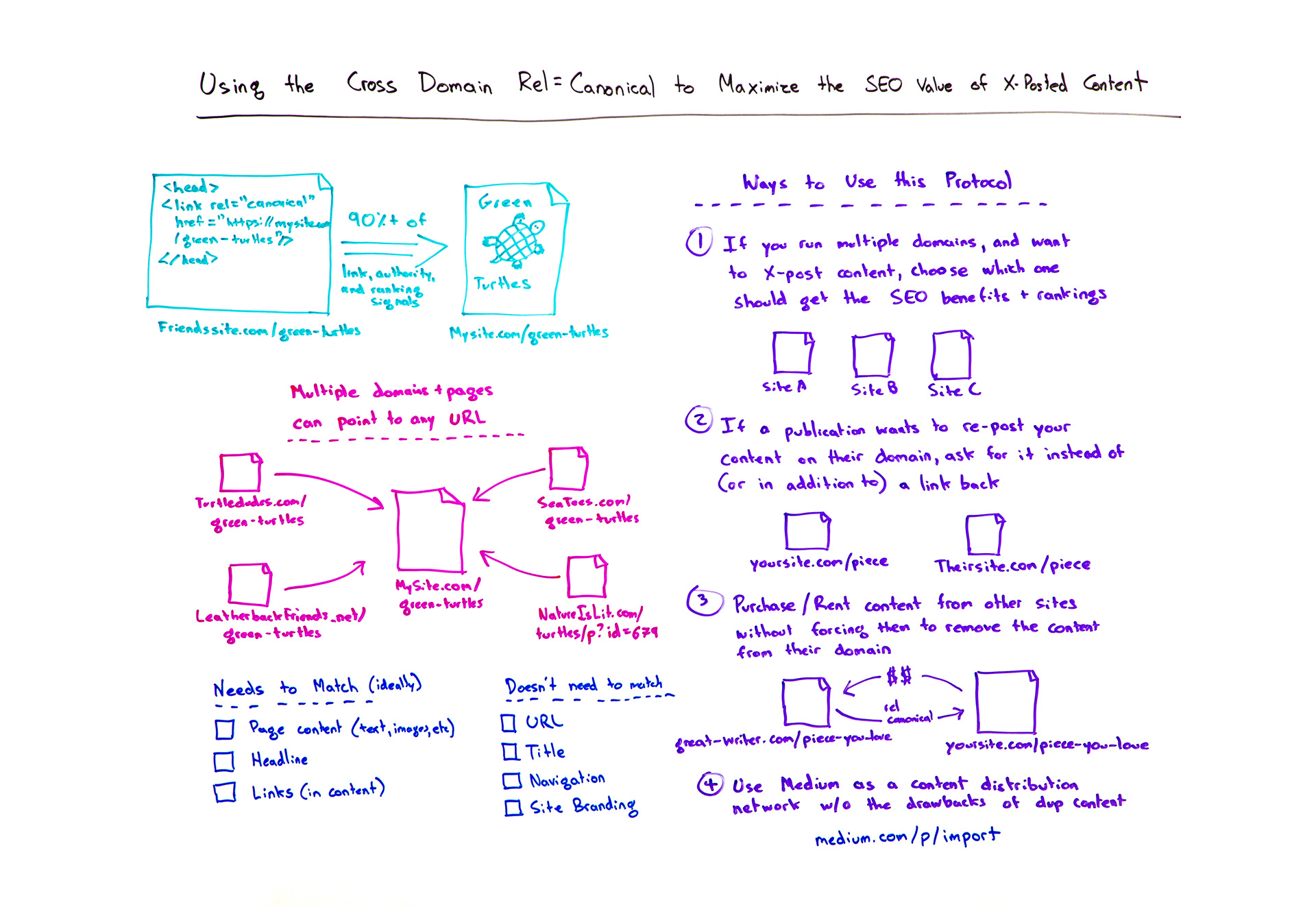
Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Howdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we're going to chat about the cross-domain rel=canonical tag. So we've talked about rel=canonical a little bit and how it can be used to take care of duplicate content issues, point Google to the right pages from potentially other pages that share similar or exactly the same content. But cross-domain rel=canonical is a unique and uniquely powerful tool that is designed to basically say, "You know what, Google? There is the same content on multiple different domains."

So in this simplistic example, MyFriendSite.com/green-turtles contains this content that I said, "Sure, it's totally fine for you, my friend, to republish, but I know I don't want SEO issues. I know I don't want duplicate content. I know I don't want a problem where my friend's site ends up outranking me, because maybe they have better links or other ranking signals, and I know that I would like any ranking credit, any link or authority signals that they accrue to actually come to my website.
There's a way that you can do this. Google introduced it back in 2009. It is the cross-domain rel=canonical. So essentially, in the header tag of the page, I can add this link, rel=canonical href — it's a link tag, so there's an href — to the place where I want the link or the canonical, in this case, to point to and then close the tag. Google will transfer over, this is an estimate, but roughly in the SEO world, we think it's pretty similar to what you get in a 301 redirect. So something above 90% of the link authority and ranking signals will transfer from FriendSite.com to MySite.com.
So my green turtles page is going to be the one that Google will be more likely to rank. As this one accrues any links or other ranking signals, that authority, those links should transfer over to my page. That's an ideal situation for a bunch of different things. I'll talk about those in a sec.
Multiple domains and pages can point to any URL

Multiple domains and pages are totally cool to point to any URL. I can do this for FriendSite.com. I can also do this for TurtleDudes.com and LeatherbackFriends.net and SeaTees.com and NatureIsLit.com. All of them can contain this cross-domain rel=canonical pointing back to the site or the page that I want it to go to. This is a great way to potentially license content out there, give people republishing permissions without losing any of the SEO value.
A few things need to match:
I. The page content really does need to match
That includes things like text, images, if you've embedded videos, whatever you've got on there.
II. The headline
Ideally, should match. It's a little less crucial than the page content, but probably you want that headline to match.
III. Links (in content)
Those should also match. This is a good way to make sure. You check one, two, three. This is a good way to make sure that Google will count that rel=canonical correctly.
Things that don't need to match:
I. The URL
No, it's fine if the URLs are different. In this case, I've got NatureIsLit.com/turtles/p?id=679. That's okay. It doesn't need to be green-turtles. I can have a different URL structure on my site than they've got on theirs. Google is just fine with that.
II. The title of the piece
Many times the cross-domain rel=canonical is used with different page titles. So if, for example, CTs.com wants to publish the piece with a different title, that's okay. I still generally recommend that the headlines stay the same, but okay to have different titles.
III. The navigation
IV. Site branding
So all the things around the content. If I've got my page here and I have like nav elements over here, nav elements down here, maybe a footer down here, a nice little logo up in the top left, that's fine if those are totally different from the ones that are on these other pages cross-domain canonically. That stuff does not need to match. We're really talking about the content inside the page that Google looks for.
Ways to use this protocol
Some great ways to use the cross-domain rel=canonical.
1. If you run multiple domains and want to cross-post content, choose which one should get the SEO benefits and rankings.

If you run multiple domains, for whatever reason, let's say you've got a set of domains and you would like the benefit of being able to publish a single piece of content, for whatever reason, across multiples of these domains that you own, but you know you don't want to deal with a duplicate content issue and you know you'd prefer for one of these domains to be the one receiving the ranking signals, cross-domain rel=canonical is your friend. You can tell Google that Site A and Site C should not get credit for this content, but Site B should get all the credit.
The issue here is don't try and do this across multiple domains. So don't say, "Oh, Site A, why don't you rel=canonical to B, and Site C, why don't you rel=canonical to D, and I'll try and get two things ranked in the top." Don't do that. Make sure all of them point to one. That is the best way to make sure that Google respects the cross-domain rel=canonical properly.
2. If a publication wants to re-post your content on their domain, ask for it instead of (or in addition to) a link back.

Second, let's say a publication reaches out to you. They're like, "Wow. Hey, we really like this piece." My wife, Geraldine, wrote a piece about Mario Batali's sexual harassment apology letter and the cinnamon rolls recipe that he strangely included in this apology. She baked those and then wrote about it. It went quite viral, got a lot of shares from a ton of powerful and well-networked people and then a bunch of publications. The Guardian reached out. An Australian newspaper reached out, and they said, "Hey, we would like to republish your piece." Geraldine talked to her agent, and they set up a price or whatever.
One of the ways that you can do this and benefit from it, not just from getting a link from The Guardian or some other newspaper, but is to say, "Hey, I will be happy to be included here. You don't even have to give me, necessarily, if you don't want to, author credit or link credit, but I do want that sweet, sweet rel=canonical." This is a great way to maximize the SEO benefit of being posted on someone else's site, because you're not just receiving a single link. You're receiving credit from all the links that that piece might generate.
Oops, I did that backwards. You want it to come from their site to your site. This is how you know Whiteboard Friday is done in one take.
3. Purchase/rent content from other sites without forcing them to remove the content from their domain.

Next, let's say I am in the opposite situation. I'm the publisher. I see a piece of content that I love and I want to get that piece. So I might say, "Wow, that piece of content is terrific. It didn't do as well as I thought it would do. I bet if we put it on our site and broadcast it with our audience, it would do incredibly well. Let's reach out to the author of the piece and see if we can purchase or rent for a time period, say two years, for the next two years we want to put the cross-domain rel=canonical on your site and point it back to us and we want to host that content. After two years, you can have it back. You can own it again."
Without forcing them to remove the content from their site, so saying you, publisher, you author can keep it on your site. We don't mind. We'd just like this tag applied, and we'd like to able to have republishing permissions on our website. Now you can get the SEO benefits of that piece of content, and they can, in exchange, get some money. So your site sending them some dollars, their site sending you the rel=canonical and the ranking authority and the link equity and all those beautiful things.
4. Use Medium as a content distribution network without the drawback of duplicate content.
Number four, Medium. Medium is a great place to publish content. It has a wide network, people who really care about consuming content. Medium is a great distribution network with one challenge. If you post on Medium, people worry that they can't post the same thing on their own site because you'll be competing with Medium.com. It's a very powerful domain. It tends to rank really well. So duplicate content is an issue, and potentially losing the rankings and the traffic that you would get from search and losing that to Medium is no fun.
But Medium has a beautiful thing. The cross-domain rel=canonical is built in to their import tool. So if you go to Medium.com/p/import and you are logged in to your Medium account, you can enter in their URL field the content that you've published on your own site. Medium will republish it on your account, and they will include the cross-domain rel=canonical back to you. Now, you can start thinking of Medium as essentially a distribution network without the penalties or problems of duplicate content issues. Really, really awesome tool. Really awesome that Medium is offering this. I hope it sticks around.
All right, everyone. I think you're going to have some excellent additional ideas for the cross-domain rel=canonical and how you have used it. We would love you to share those in the comments below, and we'll see you again next week for another edition of Whiteboard Friday. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!