vendredi 29 juin 2018
What Do SEOs Do When Google Removes Organic Search Traffic? - Whiteboard Friday
Posted by randfish
We rely pretty heavily on Google, but some of their decisions of late have made doing SEO more difficult than it used to be. Which organic opportunities have been taken away, and what are some potential solutions? Rand covers a rather unsettling trend for SEO in this week's Whiteboard Friday.

Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Howdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we're talking about something kind of unnerving. What do we, as SEOs, do as Google is removing organic search traffic?
So for the last 19 years or 20 years that Google has been around, every month Google has had, at least seasonally adjusted, not just more searches, but they've sent more organic traffic than they did that month last year. So this has been on a steady incline. There's always been more opportunity in Google search until recently, and that is because of a bunch of moves, not that Google is losing market share, not that they're receiving fewer searches, but that they are doing things that makes SEO a lot harder.
Some scary news
Things like...
- Aggressive "answer" boxes. So you search for a question, and Google provides not just necessarily a featured snippet, which can earn you a click-through, but a box that truly answers the searcher's question, that comes directly from Google themselves, or a set of card-style results that provides a list of all the things that the person might be looking for.
- Google is moving into more and more aggressively commercial spaces, like jobs, flights, products, all of these kinds of searches where previously there was opportunity and now there's a lot less. If you're Expedia or you're Travelocity or you're Hotels.com or you're Cheapflights and you see what's going on with flight and hotel searches in particular, Google is essentially saying, "No, no, no. Don't worry about clicking anything else. We've got the answers for you right here."
- We also saw for the first time a seasonally adjusted drop, a drop in total organic clicks sent. That was between August and November of 2017. It was thanks to the Jumpshot dataset. It happened at least here in the United States. We don't know if it's happened in other countries as well. But that's certainly concerning because that is not something we've observed in the past. There were fewer clicks sent than there were previously. That makes us pretty concerned. It didn't go down very much. It went down a couple of percentage points. There's still a lot more clicks being sent in 2018 than there were in 2013. So it's not like we've dipped below something, but concerning.
- New zero-result SERPs. We absolutely saw those for the first time. Google rolled them back after rolling them out. But, for example, if you search for the time in London or a Lagavulin 16, Google was showing no results at all, just a little box with the time and then potentially some AdWords ads. So zero organic results, nothing for an SEO to even optimize for in there.
- Local SERPs that remove almost all need for a website. Then local SERPs, which have been getting more and more aggressively tuned so that you never need to click the website, and, in fact, Google has made it harder and harder to find the website in both mobile and desktop versions of local searches. So if you search for Thai restaurant and you try and find the website of the Thai restaurant you're interested in, as opposed to just information about them in Google's local pack, that's frustratingly difficult. They are making those more and more aggressive and putting them more forward in the results.
Potential solutions for marketers
So, as a result, I think search marketers really need to start thinking about: What do we do as Google is taking away this opportunity? How can we continue to compete and provide value for our clients and our companies? I think there are three big sort of paths — I won't get into the details of the paths — but three big paths that we can pursue.
1. Invest in demand generation for your brand + branded product names to leapfrog declines in unbranded search.

The first one is pretty powerful and pretty awesome, which is investing in demand generation, rather than just demand serving, but demand generation for brand and branded product names. Why does this work? Well, because let's say, for example, I'm searching for SEO tools. What do I get? I get back a list of results from Google with a bunch of mostly articles saying these are the top SEO tools. In fact, Google has now made a little one box, card-style list result up at the top, the carousel that shows different brands of SEO tools. I don't think Moz is actually listed in there because I think they're pulling from the second or the third lists instead of the first one. Whatever the case, frustrating, hard to optimize for. Google could take away demand from it or click-through rate opportunity from it.
But if someone performs a search for Moz, well, guess what? I mean we can nail that sucker. We can definitely rank for that. Google is not going to take away our ability to rank for our own brand name. In fact, Google knows that, in the navigational search sense, they need to provide the website that the person is looking for front and center. So if we can create more demand for Moz than there is for SEO tools, which I think there's something like 5 or 10 times more demand already for Moz than there is tools, according to Google Trends, that's a great way to go. You can do the same thing through your content, through your social media, and through your email marketing. Even through search you can search and create demand for your brand rather than unbranded terms.
2. Optimize for additional platforms.

Second thing, optimizing across additional platforms. So we've looked and YouTube and Google Images account for about half of the overall volume that goes to Google web search. So between these two platforms, you've got a significant amount of additional traffic that you can optimize for. Images has actually gotten less aggressive. Right now they've taken away the "view image directly" link so that more people are visiting websites via Google Images. YouTube, obviously, this is a great place to build brand affinity, to build awareness, to create demand, this kind of demand generation to get your content in front of people. So these two are great platforms for that.
There are also significant amounts of web traffic still on the social web — LinkedIn, Facebook, Twitter, Pinterest, Instagram, etc., etc. The list goes on. Those are places where you can optimize, put your content forward, and earn traffic back to your websites.
3. Optimize the content that Google does show.
Local
So if you're in the local space and you're saying, "Gosh, Google has really taken away the ability for my website to get the clicks that it used to get from Google local searches," going into Google My Business and optimizing to provide information such that people who perform that query will be satisfied by Google's result, yes, they won't get to your website, but they will still come to your business, because you've optimized the content such that Google is showing, through Google My Business, such that those searchers want to engage with you. I think this sometimes gets lost in the SEO battle. We're trying so hard to earn the click to our site that we're forgetting that a lot of search experience ends right at the SERP itself, and we can optimize there too.
Results
In the zero-results sets, Google was still willing to show AdWords, which means if we have customer targets, we can use remarketed lists for search advertising (RLSA), or we can run paid ads and still optimize for those. We could also try and claim some of the data that might show up in zero-result SERPs. We don't yet know what that will be after Google rolls it back out, but we'll find out in the future.
Answers
For answers, the answers that Google is giving, whether that's through voice or visually, those can be curated and crafted through featured snippets, through the card lists, and through the answer boxes. We have the opportunity again to influence, if not control, what Google is showing in those places, even when the search ends at the SERP.
All right, everyone, thanks for watching for this edition of Whiteboard Friday. We'll see you again next week. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
jeudi 28 juin 2018
The Minimum Viable Knowledge You Need to Work with JavaScript & SEO Today
Posted by sergeystefoglo
If your work involves SEO at some level, you’ve most likely been hearing more and more about JavaScript and the implications it has on crawling and indexing. Frankly, Googlebot struggles with it, and many websites utilize modern-day JavaScript to load in crucial content today. Because of this, we need to be equipped to discuss this topic when it comes up in order to be effective.
The goal of this post is to equip you with the minimum viable knowledge required to do so. This post won’t go into the nitty gritty details, describe the history, or give you extreme detail on specifics. There are a lot of incredible write-ups that already do this — I suggest giving them a read if you are interested in diving deeper (I’ll link out to my favorites at the bottom).
In order to be effective consultants when it comes to the topic of JavaScript and SEO, we need to be able to answer three questions:
- Does the domain/page in question rely on client-side JavaScript to load/change on-page content or links?
- If yes, is Googlebot seeing the content that’s loaded in via JavaScript properly?
- If not, what is the ideal solution?
With some quick searching, I was able to find three examples of landing pages that utilize JavaScript to load in crucial content.
I’m going to be using Sitecore’s Symposium landing page through each of these talking points to illustrate how to answer the questions above.
We’ll cover the “how do I do this” aspect first, and at the end I’ll expand on a few core concepts and link to further resources.
Question 1: Does the domain in question rely on client-side JavaScript to load/change on-page content or links?
The first step to diagnosing any issues involving JavaScript is to check if the domain uses it to load in crucial content that could impact SEO (on-page content or links). Ideally this will happen anytime you get a new client (during the initial technical audit), or whenever your client redesigns/launches new features of the site.
How do we go about doing this?
Ask the client
Ask, and you shall receive! Seriously though, one of the quickest/easiest things you can do as a consultant is contact your POC (or developers on the account) and ask them. After all, these are the people who work on the website day-in and day-out!
“Hi [client], we’re currently doing a technical sweep on the site. One thing we check is if any crucial content (links, on-page content) gets loaded in via JavaScript. We will do some manual testing, but an easy way to confirm this is to ask! Could you (or the team) answer the following, please?
1. Are we using client-side JavaScript to load in important content?
2. If yes, can we get a bulleted list of where/what content is loaded in via JavaScript?”
Check manually
Even on a large e-commerce website with millions of pages, there are usually only a handful of important page templates. In my experience, it should only take an hour max to check manually. I use the Chrome Web Developers plugin, disable JavaScript from there, and manually check the important templates of the site (homepage, category page, product page, blog post, etc.)

In the example above, once we turn off JavaScript and reload the page, we can see that we are looking at a blank page.
As you make progress, jot down notes about content that isn’t being loaded in, is being loaded in wrong, or any internal linking that isn’t working properly.
At the end of this step we should know if the domain in question relies on JavaScript to load/change on-page content or links. If the answer is yes, we should also know where this happens (homepage, category pages, specific modules, etc.)
Crawl
You could also crawl the site (with a tool like Screaming Frog or Sitebulb) with JavaScript rendering turned off, and then run the same crawl with JavaScript turned on, and compare the differences with internal links and on-page elements.
For example, it could be that when you crawl the site with JavaScript rendering turned off, the title tags don’t appear. In my mind this would trigger an action to crawl the site with JavaScript rendering turned on to see if the title tags do appear (as well as checking manually).
Example
For our example, I went ahead and did a manual check. As we can see from the screenshot below, when we disable JavaScript, the content does not load.

In other words, the answer to our first question for this pages is “yes, JavaScript is being used to load in crucial parts of the site.”
Question 2: If yes, is Googlebot seeing the content that’s loaded in via JavaScript properly?
If your client is relying on JavaScript on certain parts of their website (in our example they are), it is our job to try and replicate how Google is actually seeing the page(s). We want to answer the question, “Is Google seeing the page/site the way we want it to?”
In order to get a more accurate depiction of what Googlebot is seeing, we need to attempt to mimic how it crawls the page.
How do we do that?
Use Google’s new mobile-friendly testing tool
At the moment, the quickest and most accurate way to try and replicate what Googlebot is seeing on a site is by using Google’s new mobile friendliness tool. My colleague Dom recently wrote an in-depth post comparing Search Console Fetch and Render, Googlebot, and the mobile friendliness tool. His findings were that most of the time, Googlebot and the mobile friendliness tool resulted in the same output.
In Google’s mobile friendliness tool, simply input your URL, hit “run test,” and then once the test is complete, click on “source code” on the right side of the window. You can take that code and search for any on-page content (title tags, canonicals, etc.) or links. If they appear here, Google is most likely seeing the content.

Search for visible content in Google
It’s always good to sense-check. Another quick way to check if GoogleBot has indexed content on your page is by simply selecting visible text on your page, and doing a site:search for it in Google with quotations around said text.
In our example there is visible text on the page that reads…
"Whether you are in marketing, business development, or IT, you feel a sense of urgency. Or maybe opportunity?"
When we do a site:search for this exact phrase, for this exact page, we get nothing. This means Google hasn’t indexed the content.
 Crawling with a tool
Crawling with a tool
Most crawling tools have the functionality to crawl JavaScript now. For example, in Screaming Frog you can head to configuration > spider > rendering > then select “JavaScript” from the dropdown and hit save. DeepCrawl and SiteBulb both have this feature as well.
From here you can input your domain/URL and see the rendered page/code once your tool of choice has completed the crawl.
Example:
When attempting to answer this question, my preference is to start by inputting the domain into Google’s mobile friendliness tool, copy the source code, and searching for important on-page elements (think title tag, <h1>, body copy, etc.) It’s also helpful to use a tool like diff checker to compare the rendered HTML with the original HTML (Screaming Frog also has a function where you can do this side by side).
For our example, here is what the output of the mobile friendliness tool shows us.

After a few searches, it becomes clear that important on-page elements are missing here.
We also did the second test and confirmed that Google hasn’t indexed the body content found on this page.
The implication at this point is that Googlebot is not seeing our content the way we want it to, which is a problem.
Let’s jump ahead and see what we can recommend the client.
Question 3: If we’re confident Googlebot isn’t seeing our content properly, what should we recommend?
Now we know that the domain is using JavaScript to load in crucial content and we know that Googlebot is most likely not seeing that content, the final step is to recommend an ideal solution to the client. Key word: recommend, not implement. It’s 100% our job to flag the issue to our client, explain why it’s important (as well as the possible implications), and highlight an ideal solution. It is 100% not our job to try to do the developer’s job of figuring out an ideal solution with their unique stack/resources/etc.
How do we do that?
You want server-side rendering
The main reason why Google is having trouble seeing Sitecore’s landing page right now, is because Sitecore’s landing page is asking the user (us, Googlebot) to do the heavy work of loading the JavaScript on their page. In other words, they’re using client-side JavaScript.
Googlebot is literally landing on the page, trying to execute JavaScript as best as possible, and then needing to leave before it has a chance to see any content.
The fix here is to instead have Sitecore’s landing page load on their server. In other words, we want to take the heavy lifting off of Googlebot, and put it on Sitecore’s servers. This will ensure that when Googlebot comes to the page, it doesn’t have to do any heavy lifting and instead can crawl the rendered HTML.
In this scenario, Googlebot lands on the page and already sees the HTML (and all the content).
There are more specific options (like isomorphic setups)
This is where it gets to be a bit in the weeds, but there are hybrid solutions. The best one at the moment is called isomorphic.
In this model, we're asking the client to load the first request on their server, and then any future requests are made client-side.
So Googlebot comes to the page, the client’s server has already executed the initial JavaScript needed for the page, sends the rendered HTML down to the browser, and anything after that is done on the client-side.
If you’re looking to recommend this as a solution, please read this post from the AirBNB team which covers isomorphic setups in detail.
AJAX crawling = no go
I won’t go into details on this, but just know that Google’s previous AJAX crawling solution for JavaScript has since been discontinued and will eventually not work. We shouldn’t be recommending this method.
(However, I am interested to hear any case studies from anyone who has implemented this solution recently. How has Google responded? Also, here’s a great write-up on this from my colleague Rob.)
Summary
At the risk of severely oversimplifying, here's what you need to do in order to start working with JavaScript and SEO in 2018:
- Know when/where your client’s domain uses client-side JavaScript to load in on-page content or links.
- Ask the developers.
- Turn off JavaScript and do some manual testing by page template.
- Crawl using a JavaScript crawler.
- Check to see if GoogleBot is seeing content the way we intend it to.
- Google’s mobile friendliness checker.
- Doing a site:search for visible content on the page.
- Crawl using a JavaScript crawler.
- Give an ideal recommendation to client.
- Server-side rendering.
- Hybrid solutions (isomorphic).
- Not AJAX crawling.
Further resources
- The Ultimate Guide to JavaScript SEO
- JavaScript and SEO: The Difference Between Crawling and Indexing
- Core Principles of SEO for JavaScript
- How to Audit JavaScript for SEO
- JavaScript SEO Resources
- View Source: Why it Still Matters and How to Quickly Compare it to a Rendered DOM
I’m really interested to hear about any of your experiences with JavaScript and SEO. What are some examples of things that have worked well for you? What about things that haven’t worked so well? If you’ve implemented an isomorphic setup, I’m curious to hear how that’s impacted how Googlebot sees your site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
mercredi 27 juin 2018
mardi 26 juin 2018
lundi 25 juin 2018
vendredi 22 juin 2018
The Goal-Based Approach to Domain Selection - Whiteboard Friday
Posted by KameronJenkins
Choosing a domain is a big deal, and there's a lot that goes into it. Even with everything that goes into determining your URL, there are two essential questions to ask that ought to guide your decision-making: what are my goals, and what's best for my users? In today's edition of Whiteboard Friday, we're beyond delighted to welcome Kameron Jenkins, our SEO Wordsmith, to the show to teach us all about how to select a domain that aligns with and supports your business goals.

Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Hey, everyone. Welcome to this week's edition of Whiteboard Friday. My name is Kameron Jenkins, and I am the SEO Wordsmith here at Moz. Today we're going to be talking about a goals-based approach to choosing a domain type or a domain selection.

There are a lot of questions in the SEO industry right now, and as an agency, I used to work at an agency, and a lot of times our clients would ask us, "Should I do a microsite? Should I do a subdomain? Should I consolidate all my sites?" There is a lot of confusion about the SEO impact of all of these different types of domain choices, and there certainly are SEO ramifications for each type, but today we're going to be taking a slightly different approach and focusing on goals first. What are your business goals? What are your goals for your website? What are your goals for your users? And then choosing a domain that matches those goals. By the end, instead of what's better for SEO, we're going to hopefully have answered, "What best suits my unique goals?"
Before we start...define!
Before we start, let's launch into some quick definitions just so we all kind of know what we're talking about and why all the different terminology we're going to be using.
Main domain
Main domain, this is often called a root domain in some cases. That's anything that precedes your dot com or other TLD. So YourSite.com, it lives right before that.

Subdomain
A subdomain is a third-level domain name for your domain. So example, Blog.YourSite.com, that would be a subdomain.
Subfolder
A subfolder, or some people call this subdirectory, those are folders trailing the dot com. An example would be YourSite.com/blog. That /blog is the folder. That's a subfolder.
 Microsite
Microsite
A microsite, there's a lot of different terminology around this type of domain selection, but it's just a completely separate domain from your main domain. The focus is usually a little bit more niche than the topic of your main website.

That would be YourSite1.com and YourSite2.com. They're two totally, completely separate domains.
Business goals that can impact domain structure
Next we're going to start talking about business goals that can impact domain structure. There are a lot of different business goals. You want to grow revenue. You want more customers. But we're specifically here going to be talking about the types of business goals that can impact domain selection.
1. Expand locations/products/services
The first one here that we're going to talk about is the business wants to expand their locations, their products, or their services. They want to grow. They want to expand in some way. An example I like to use is say this clothing store has two locations. They have two storefronts. They have one in Dallas and one in Fort Worth.
So they launch two websites — CoolClothesDallas.com and CoolClothesFortWorth.com. But the problem with that is if you want to grow, you're going to open stores in Austin, Houston, etc. You've set the precedent that you're going to have a different domain for every single location, which is not really future-proof. It's hard to scale. Every time you launch a brand-new website, that's a lot of work to launch it, a lot of work to maintain it.
So if you plan on growing and getting into new locations or products or services or whatever it might be, just make sure you select a domain structure that's going to accommodate that. In particular, I would say a main root domain with subfolders for the different products or services you have is probably the best bet for that situation. So you have YourSite.com/Product1, /Product2, and you talk about it in that sense because it's all related. It's all the same topic. It's more future-proof. It's easier to add a page than it is to launch a whole new domain.
2. Set apart distinct facets of business
So another business goal that can affect your domain structure would be that the business wants to set apart distinct facets within their business. An example I found that was actually kind of helpful is Apple.com has a subdomain for Trailers.Apple.com.
Now, I'm not Apple. I don't really know exactly why they do this, but I have to imagine that it was because there are very different intents and uses for those different types of content that live on the subdomain versus the main site. So Trailers has movie trailers, lots of different content, and Apple.com is talking more about their consumer products, more about that type of thing.
So the audiences are slightly different. The intents are very different. In that situation, if you have a situation like that and that matches what your business is encountering, you want to set it apart, it has a different audience, you might want to consider a subdomain or maybe even a microsite. Just keep in mind that it takes effort to maintain each domain that you launch.
So make sure you have the resources to do this. You could, if you didn't have the resources, put it all on the main domain. But if you want a little bit more separation, the different aspects of your business are very disparate and you don't want them really associated on the same domain, you could separate it out with a subdomain or a microsite. Just, again, make sure that you have the resources to maintain it, because while both have equal ability to rank, it's the effort that increases with each new website you launch.
3. Differentiate uniquely branded sub-departments
Three, another goal is to differentiate uniquely branded sub-departments. There is a lot of this I've noticed in the healthcare space. So the sites that I've worked on, say they have Joe Smith Health, and this is the health system, the umbrella health system. Then within that you have Joe Smith Endocrinology.
Usually those types of situations they have completely different branding. They're in a different location. They reach a different audience, a different community. So in those situations I've seen that, especially healthcare, they usually have the resources to launch and maintain a completely different domain for that uniquely branded sub-department, and that might make sense.
Again, make sure you have the resources. But if it's very, very different, whether in branding or audience or intent, than the content that's on your main website, then I might consider separating them. Another example of this is sometimes you have a parent company and they own a lot of different companies, but that's about where the similarities stop.
They're just only owned by the parent company. All the different subcompanies don't have anything to do with each other. I would probably say it's wisest to separate those into their own unique domains. They probably definitely have unique branding. They're totally different companies. They're just owned by the same company. In those situations it might make sense, again, to separate them, but just know that they're not going to have any ranking benefit for each other because they're just completely separate domains.
4. Temporary or seasonal campaigns
The fourth business goal we're going to talk about is a temporary or a seasonal campaign. This one is not as common, but I figured I would just mention it. Sometimes a business will want to run a conference or sponsor an event or get a lot of media attention around some initiative that's separate from what their business does or offers, and it's just more of an events-based, seasonal type of thing.
In those situations it might make sense to do a microsite that's completely branded for that event. It's not necessary. For example, Moz has MozCon, and that's located on subfolder Moz.com/MozCon. You don't have to do that, but it certainly is an option for you if you want to uniquely brand it.
It can also be really good for press. I've noticed just in my experience, I don't know if this is widely common, but sometimes the press tends to just link to the homepage because that's what they know. They don't link to a specific page on your site. They don't know always where it's located. It's just easier to link to the main domain. If you want to build links specifically for this event that are really relevant, you might want to do a microsite or something like that.
Just make sure that when the event is over, don't just let it float out there and die. Especially if you build links and attention around it, make sure you 301 that back to your main website as long as that makes sense. So temporary or seasonal campaigns, that could be the way to go — microsite, subfolder. You have some options there.
5. Test out a new agency or consultant
Then finally the last goal we're going to be talking about that could impact domain structure is testing out a new agency or consultant.
Now this one holds a special place in my heart having worked for an agency prior to this for almost seven years. It's actually really common, and I can empathize with businesses who are in this situation. They are about to hand over their keys to their domain to a brand-new company. They don't quite know if they trust them yet.
Especially this is concerning if a business has a really strong domain that they've built up over time. It can be really scary to just let someone take over your domain. In some cases I have encountered, the business goes, "Hey, we'd love to test you out. We think you're great.However, you can't touch the main domain.You have to do your SEO somewhere else." That's okay, but we're kind of handcuffed in that situation.
You would have to, at that point, use a subdomain or a microsite, just a completely different website. If you can't touch the main domain, you don't really have many other options than that. You just have to launch on a brand-new thing. In that situation, it's a little frustrating, actually quite frustrating for SEOs because they're starting from nothing.
They have no authority inherited from that main domain. They're starting from square one. They have to build that up over time. While that's possible, just know that it kind of sets you back. You're way behind the starting line in that situation with using a subdomain or a microsite, not being able to touch that main domain.
If you find yourself in this situation and you can negotiate this, just make sure that the company that's hiring you is giving you enough time to prove the value of SEO. This is tried-and-true for a reason, but SEO is a marathon. It's not a sprint. It's not pay to play like paid advertising is. In that situation, just make sure that whoever is hiring you is giving you enough time.
Enough time is kind of dependent on how competitive the goals are. If they're asking you, "Hey, I'm going to test you out for this really, really competitive, high-volume keyword or group of keywords and you only have one month to do it," you're kind of set up to fail in that situation. Either ask them for more time, or I probably wouldn't take that job. So testing out a new agency or consultant is definitely something that can impact your ability to launch on one domain type versus another.
Pitfalls!
Now that we've talked about all of those, I'm just going to wrap up with some pitfalls. A lot of these are going to be repeat, but just as a way of review just watch out for these things.

⃠ Failing to future-proof
Like I said earlier, if you're planning on growing in the future, just make sure that your domain matches your future plans.
⃠ Exact-match domains
There's nothing inherently wrong with exact-match domains. It's just that you can't expect to launch a microsite with a bunch of keywords that are relevant to your business in your domain and just set it and forget it and hope that the keywords in the domain alone are what's going to get it to rank. That doesn't work anymore. It's not worked for a while. You have to actually proactively be adding value to that microsite.
Maybe you've decided that that makes sense for your business. That's great. Just make sure that you put in the resources to make it valuable outside of just the keywords in the domain.
⃠ Over-fragmenting
One thing I like to say is, "Would you rather have 3 websites with 10 backlinks each, or 1 website with 30 backlinks?" That's just a way to illustrate that if you don't have the resources to equally dedicate to each of those domains or subdomains or microsites or whatever you decided to launch, it's not going to be as strong.
Usually what I see when I evaluate a customer or a client's domain structure, usually there is one standout domain that has all of the content, all of the authority, all of the backlinks, and then the other ones just kind of suffer and they're usually stronger together than they are apart. So while it is totally possible to do separate websites, just make sure that you don't fragment so much that you're spread too thin to actually do anything effective on the SEO front.
⃠ Ignoring user experience
Look at your websites from the eyes of your users. If someone is going to go to the search results page and Google search your business name, are they going to see five websites there? That's kind of confusing unless they're very differently branded, different intents. They'll probably be confused.
Like, "Is this where I go to contact your business? How about this? Is it this?" There are just a lot of different ways that can cause confusion, so just keep that in mind. Also if you have a website where you're addressing two completely different audiences within your website — if a consumer, for example, can be browsing blouses and then somehow end up accidentally on a section that's only for employees — that's a little confusing for user experience.
Make sure you either gate that or make it a subdomain or a microsite. Just separate them if that would be confusing for your main user base.
⃠ Set it and forget it
Like I said, I keep repeating this just because it's so, so important. Every type of domain has equal ability to rank. It really does.
It's just the effort that gets harder and harder with each new website. Just make sure that you don't just decide to do microsites and subdomains and then don't do anything with them. That can be a totally fine choice. Just make sure that you don't set it and forget it, that you actually have the resources and you have the ability to keep building those up.
⃠ Intent overlap between domains
The last one I'll talk about in the pitfall department is intent overlap between domains.
I see this one actually kind of a lot. It can be like a winery. So they have tastings.winery.com or something like that. In that situation, their Tasting subdomain talks all about their wine tasting, their tasting room. It's very focused on that niche of their business. But then on Winery.com they also have extensive content about tastings. Well, you've got overlap there, and you're kind of making yourself do more work than you have to.
I would choose one or the other and not both. Just make sure that there's no overlap there if you do choose to do separate domains, subdomains, microsites, that kind of thing. Make sure that there's no overlap and each of them has a distinct purpose.
Two important questions to focus on:

Now that we're to the end of this, I really want the takeaway to be these two questions. I think this will make domain selection a lot easier when you focus on these two questions.
What am I trying to accomplish? What are the goals? What am I trying to do? Just focus on that first. Then second of all, and probably most important, what is best for my users? So focus on your goals, focus on your users, and I think the domain selection process will be a lot easier. It's not easy by any means.
There are some very complicated situations, but I think, in the end, it's going to be a lot easier if you focus on your goals and your users. If you have any comments regarding domain selection that you think would be helpful for others to know, please share it in the comments below. That's it for this week's Whiteboard Friday, and come back next week for another one. Thanks everybody.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
mercredi 20 juin 2018
mardi 19 juin 2018
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
- The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
- The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
- When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
- The review pages of client & competitors all had rating rich snippets on Google.
- All the competitors had rating rich snippets on Bing; however, the client did not.
- The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
- Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
- A website was randomly throwing 302 errors.
- This never happened in the browser and only in crawlers.
- User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
- You’re underperforming from where you should be.
- When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
- You’ve suffered a sudden traffic drop.
- Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
- The wrong page is ranking for the wrong query.
- In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
- A website that has a lot of client-side JavaScript.
- Bigger, older websites with more legacy.
- Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
- Robots.txt: Open up Search Console and check in the robots.txt validator.
- User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
- To get the user agent switcher, open Dev Tools.
- Check the console drawer is open (the toggle is the Escape key)
- Hit the … and open "Network conditions"
- Here, select your user agent!

- IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
- Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
- I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
- No-index
- Canonical
- Mobile alternate tags
- AMP alternate tags
An example of providing mixed messages would be:
- No-indexing page A
- Page B canonicals to page A
Or:
- Page A has a canonical in a header to A with a parameter
- Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
- Sitemap
- Example: Mobile alternate tags can sit in a sitemap
- HTTP headers
- Example: Canonical and meta robots can be set in headers.
- HTML head
- This is where you’re probably looking, you’ll need this one for a comparison.
- JavaScript-rendered vs hard-coded directives
- You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
- Google Search Console settings
- There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!

4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
- Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
- Resources: Is Google downloading all the resources of the page?
- Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
- Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
- It will crawl more than us
- It is obviously a bot, rather than a human pretending to be a bot
- It will crawl at different times of day
This means that:
- If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
- Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
- Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
- What happens to the servers under heavy load?
- When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
- Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
- If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
- Fetch & Render
- Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
- Mobile-friendly test
- Shows: Rendered DOM and returns rendered DOM for you to read.
- Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
- Googlebot crawls with cookies cleared between page requests
- Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
- Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
- Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
- Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
- JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
- There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
- Google’s cache
- Shows: Source code
- While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
- Site searches for specific content
- Shows: A tiny snippet of rendered content.
- By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
- Better yet, do the same thing with a rank tracker, to see if it changes over time.
- Storing the actual rendered DOM
- Shows: Rendered DOM
- Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
- This excellent talk, How does Google work - Paul Haahr, is a must-listen.
- At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
- Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
- How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
- Similar/duplicate content to the pages that have the problem.
- This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
- De-duplication of content
- Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
- Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
- Google can consistently crawl our pages as intended.
- We’re sending Google consistent signals about the status of our page.
- Google is consistently rendering our pages as we expect.
- Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
- Look for errors
- Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.

An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie">
</div>
<p> <h1 itemprop="name">Avatar</h1>
</p>
<p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span>
</p>
<p> <span itemprop="genre">Science fiction</span>
</p>
<p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a>
</p>
<p></div>
</p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
- <title>
- <style>
- <base>
- <link>
- <meta>
- <script>
- <noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
- 302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
- 301 to https://www.client.com - This was the blanket HTTPS redirect
- 302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
samedi 16 juin 2018
vendredi 15 juin 2018
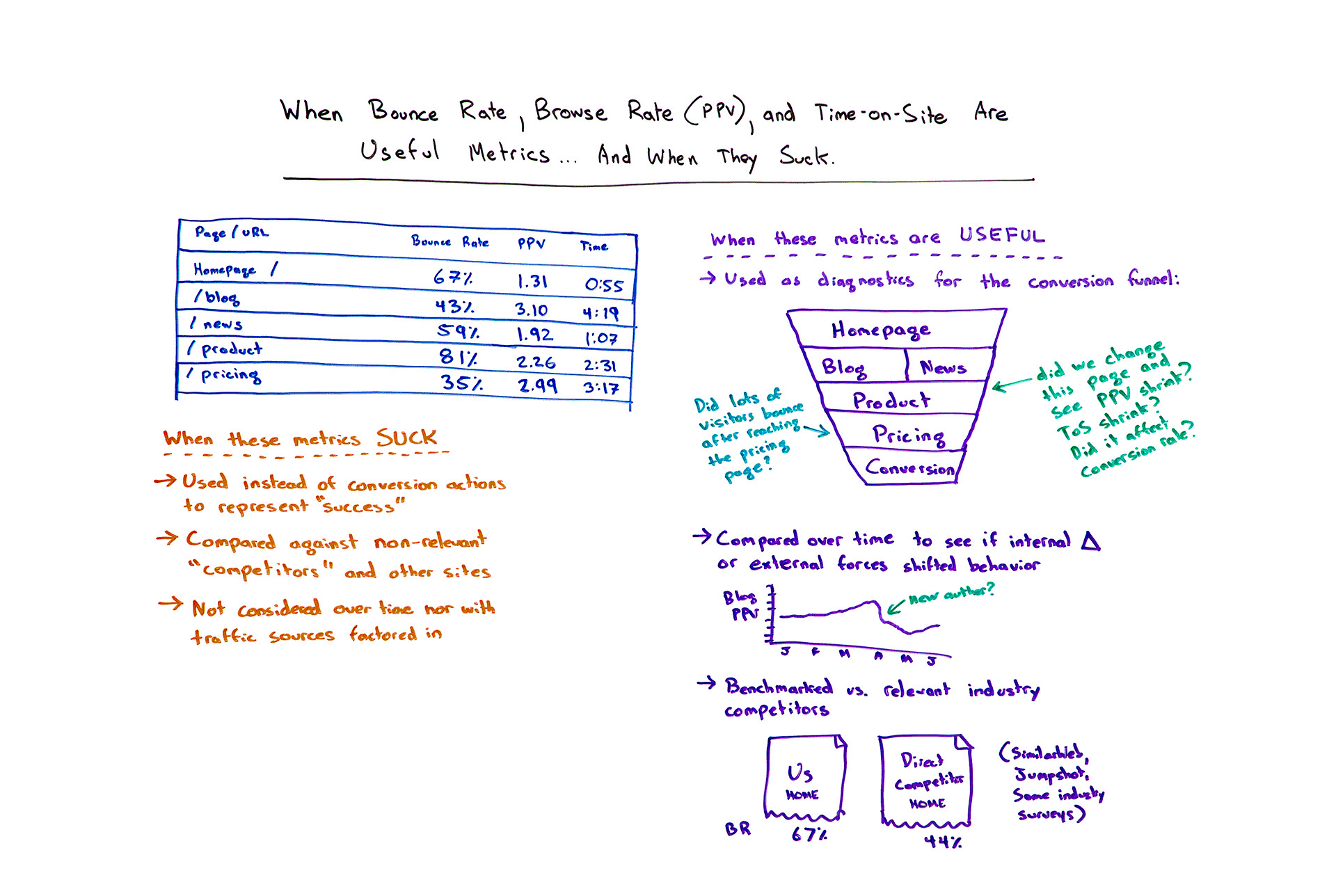
When Bounce Rate, Browse Rate (PPV), and Time-on-Site Are Useful Metrics... and When They Aren't - Whiteboard Friday
Posted by randfish
When is it right to use metrics like bounce rate, pages per visit, and time on site? When are you better off ignoring them? There are endless opinions on whether these kinds of metrics are valuable or not, and as you might suspect, the answer is found in the shades of grey. Learn what Rand has to say about the great metrics debate in today's episode of Whiteboard Friday.
Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Howdy, Moz fans, and welcome to another edition of Whiteboard Friday. This week we're chatting about times at which bounce rate, browse rate, which is pages per visit, and time on site are terrible metrics and when they're actually quite useful metrics.

This happens quite a bit. I see in the digital marketing world people talking about these metrics as though they are either dirty-scum, bottom-of-the-barrel metrics that no one should pay any attention to, or that they are these lofty, perfect metrics that are what we should be optimizing for. Neither of those is really accurate. As is often the case, the truth usually lies somewhere in between.
So, first off, some credit to Wil Reynolds, who brought this up during a discussion that I had with him at Siege Media's offices, an interview that Ross Hudgens put together with us, and Sayf Sharif from Seer Interactive, their Director of Analytics, who left an awesome comment about this discussion on the LinkedIn post of that video. We'll link to those in this Whiteboard Friday.
So Sayf and Wil were both basically arguing that these are kind of crap metrics. We don't trust them. We don't use them a lot. I think, a lot of the time, that makes sense.
Instances when these metrics aren't useful
Here's when these metrics, that bounce rate, pages per visit, and time on site kind of suck.
1. When they're used instead of conversion actions to represent "success"
So they suck when you use them instead of conversion actions. So a conversion is someone took an action that I wanted on my website. They filled in a form. They purchased a product. They put in their credit card. Whatever it is, they got to a page that I wanted them to get to.
Bounce rate is basically the average percent of people who landed on a page and then left your website, not to continue on any other page on that site after visiting that page.
Pages per visit is essentially exactly what it sounds like, the average number of pages per visit for people who landed on that particular page. So people who came in through one of these pages, how many pages did they visit on my site.
Then time on site is essentially a very raw and rough metric. If I leave my computer to use the restroom or I basically switch to another tab or close my browser, it's not necessarily the case that time on site ends right then. So this metric has a lot of imperfections. Now, averaged over time, it can still be directionally interesting.
But when you use these instead of conversion actions, which is what we all should be optimizing for ultimately, you can definitely get into some suckage with these metrics.
2. When they're compared against non-relevant "competitors" and other sites
When you compare them against non-relevant competitors, so when you compare, for example, a product-focused, purchase-focused site against a media-focused site, you're going to get big differences. First off, if your pages per visit look like a media site's pages per visit and you're product-focused, that is crazy. Either the media site is terrible or you're doing something absolutely amazing in terms of keeping people's attention and energy.
Time on site is a little bit misleading in this case too, because if you look at the time on site, again, of a media property or a news-focused, content-focused site versus one that's very e-commerce focused, you're going to get vastly different things. Amazon probably wants your time on site to be pretty small. Dell wants your time on site to be pretty small. Get through the purchase process, find the computer you want, buy it, get out of here. If you're taking 10 minutes to do that or 20 minutes to do that instead of 5, we've failed. We haven't provided a good enough experience to get you quickly through the purchase funnel. That can certainly be the case. So there can be warring priorities inside even one of these metrics.
3. When they're not considered over time or with traffic sources factored in
Third, you get some suckage when they are not considered over time or against the traffic sources that brought them in. For example, if someone visits a web page via a Twitter link, chances are really good, really, really good, especially on mobile, that they're going to have a high bounce rate, a low number of pages per visit, and a low time on site. That's just how Twitter behavior is. Facebook is quite similar.
Now, if they've come via a Google search, an informational Google search and they've clicked on an organic listing, you should see just the reverse. You should see a relatively good bounce rate. You should see a relatively good pages per visit, well, a relatively higher pages per visit, a relatively higher time on site.
Instances when these metrics are useful
1. When they're used as diagnostics for the conversion funnel
So there's complexity inside these metrics for sure. What we should be using them for, when these metrics are truly useful is when they are used as a diagnostic. So when you look at a conversion funnel and you see, okay, our conversion funnel looks like this, people come in through the homepage or through our blog or news sections, they eventually, we hope, make it to our product page, our pricing page, and our conversion page.

We have these metrics for all of these. When we make changes to some of these, significant changes, minor changes, we don't just look at how conversion performs. We also look at whether things like time on site shrank or whether people had fewer pages per visit or whether they had a higher bounce rate from some of these sections.
So perhaps, for example, we changed our pricing and we actually saw that people spent less time on the pricing page and had about the same number of pages per visit and about the same bounce rate from the pricing page. At the same time, we saw conversions dip a little bit.
Should we intuit that pricing negatively affected our conversion rate? Well, perhaps not. Perhaps we should look and see if there were other changes made or if our traffic sources were in there, because it looks like, given that bounce rate didn't increase, given that pages per visit didn't really change, given that time on site actually went down a little bit, it seems like people are making it just fine through the pricing page. They're making it just fine from this pricing page to the conversion page, so let's look at something else.
This is the type of diagnostics that you can do when you have metrics at these levels. If you've seen a dip in conversions or a rise, this is exactly the kind of dig into the data that smart, savvy digital marketers should and can be doing, and I think it's a powerful, useful tool to be able to form hypotheses based on what happens.
So again, another example, did we change this product page? We saw pages per visit shrink and time on site shrink. Did it affect conversion rate? If it didn't, but then we see that we're getting fewer engaged visitors, and so now we can't do as much retargeting and we're losing email signups, maybe this did have a negative effect and we should go back to the other one, even if conversion rate itself didn't seem to take a particular hit in this case.
2. When they're compared over time to see if internal changes or external forces shifted behavior
Second useful way to apply these metrics is compared over time to see if your internal changes or some external forces shifted behavior. For example, we can look at the engagement rate on the blog. The blog is tough to generate as a conversion event. We could maybe look at subscriptions, but in general, pages per visit is a nice one for the blog. It tells us whether people make it past the page they landed on and into deeper sections, stick around our site, check out what we do.

So if we see that it had a dramatic fall down here in April and that was when we installed a new author and now they're sort of recovering, we can say, "Oh, yeah, you know what? That takes a little while for a new blog author to kind of come up to speed. We're going to give them time," or, "Hey, we should interject here. We need to jump in and try and fix whatever is going on."
3. When they're benchmarked versus relevant industry competitors
Third and final useful case is when you benchmark versus truly relevant industry competitors. So if you have a direct competitor, very similar focus to you, product-focused in this case with a homepage and then some content sections and then a very focused product checkout, you could look at you versus them and their homepage and your homepage.

If you could get the data from a source like SimilarWeb or Jumpshot, if there's enough clickstream level data, or some savvy industry surveys that collect this information, and you see that you're significantly higher, you might then take a look at what are they doing that we're not doing. Maybe we should use them when we do our user research and say, "Hey, what's compelling to you about this that maybe is missing here?"
Otherwise, a lot of the time people will take direct competitors and say, "Hey, let's look at what our competition is doing and we'll consider that best practice." But if you haven't looked at how they're performing, how people are getting through, whether they're engaging, whether they're spending time on that site, whether they're making it through their different pages, you don't know if they actually are best practices or whether you're about to follow a laggard's example and potentially hurt yourself.
So definitely a complex topic, definitely many, many different things that go into the uses of these metrics, and there are some bad and good ways to use them. I agree with Sayf and with Wil, but I think there are also some great ways to apply them. I would love to hear from you if you've got examples of those down in the comments. We'll see you again next week for another edition of Whiteboard Friday. Take care.
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
mercredi 13 juin 2018
mardi 12 juin 2018
Trust Your Data: How to Efficiently Filter Spam, Bots, & Other Junk Traffic in Google Analytics
Posted by Carlosesal
There is no doubt that Google Analytics is one of the most important tools you could use to understand your users' behavior and measure the performance of your site. There's a reason it's used by millions across the world.
But despite being such an essential part of the decision-making process for many businesses and blogs, I often find sites (of all sizes) that do little or no data filtering after installing the tracking code, which is a huge mistake.
Think of a Google Analytics property without filtered data as one of those styrofoam cakes with edible parts. It may seem genuine from the top, and it may even feel right when you cut a slice, but as you go deeper and deeper you find that much of it is artificial.

If you're one of those that haven’t properly configured their Google Analytics and you only pay attention to the summary reports, you probably won't notice that there's all sorts of bogus information mixed in with your real user data.
And as a consequence, you won't realize that your efforts are being wasted on analyzing data that doesn't represent the actual performance of your site.
To make sure you're getting only the real ingredients and prevent you from eating that slice of styrofoam, I'll show you how to use the tools that GA provides to eliminate all the artificial excess that inflates your reports and corrupts your data.
Common Google Analytics threats
As most of the people I've worked with know, I’ve always been obsessed with the accuracy of data, mainly because as a marketer/analyst there's nothing worse than realizing that you’ve made a wrong decision because your data wasn’t accurate. That’s why I’m continually exploring new ways of improving it.

As a result of that research, I wrote my first Moz post about the importance of filtering in Analytics, specifically about ghost spam, which was a significant problem at that time and still is (although to a lesser extent).
While the methods described there are still quite useful, I’ve since been researching solutions for other types of Google Analytics spam and a few other threats that might not be as annoying, but that are equally or even more harmful to your Analytics.

Let’s review, one by one.
Ghosts, crawlers, and other types of spam
The GA team has done a pretty good job handling ghost spam. The amount of it has been dramatically reduced over the last year, compared to the outbreak in 2015/2017.
However, the millions of current users and the thousands of new, unaware users that join every day, plus the majority's curiosity to discover why someone is linking to their site, make Google Analytics too attractive a target for the spammers to just leave it alone.

The same logic can be applied to any widely used tool: no matter what security measures it has, there will always be people trying to abuse its reach for their own interest. Thus, it's wise to add an extra security layer.
Take, for example, the most popular CMS: Wordpress. Despite having some built-in security measures, if you don't take additional steps to protect it (like setting a strong username and password or installing a security plugin), you run the risk of being hacked.

The same happens to Google Analytics, but instead of plugins, you use filters to protect it.
In which reports can you look for spam?
Spam traffic will usually show as a Referral, but it can appear in any part of your reports, even in unsuspecting places like a language or page title.

Sometimes spammers will try to fool by using misleading URLs that are very similar to known websites, or they may try to get your attention by using unusual characters and emojis in the source name.

Independently of the type of spam, there are 3 things you always should do when you think you found one in your reports:

- Never visit the suspicious URL. Most of the time they'll try to sell you something or promote their service, but some spammers might have some malicious scripts on their site.
- This goes without saying, but never install scripts from unknown sites; if for some reason you did, remove it immediately and scan your site for malware.
- Filter out the spam in your Google Analytics to keep your data clean (more on that below).
If you're not sure whether an entry on your report is real, try searching for the URL in quotes (“example.com”). Your browser won’t open the site, but instead will show you the search results; if it is spam, you'll usually see posts or forums complaining about it.
If you still can’t find information about that particular entry, give me a shout — I might have some knowledge for you.
Bot traffic
A bot is a piece of software that runs automated scripts over the Internet for different purposes.
There are all kinds of bots. Some have good intentions, like the bots used to check copyrighted content or the ones that index your site for search engines, and others not so much, like the ones scraping your content to clone it.

2016 bot traffic report. Source: Incapsula
In either case, this type of traffic is not useful for your reporting and might be even more damaging than spam both because of the amount and because it's harder to identify (and therefore to filter it out).
It's worth mentioning that bots can be blocked from your server to stop them from accessing your site completely, but this usually involves editing sensible files that require high technical knowledge, and as I said before, there are good bots too.
So, unless you're receiving a direct attack that's skewing your resources, I recommend you just filter them in Google Analytics.
In which reports can you look for bot traffic?
Bots will usually show as Direct traffic in Google Analytics, so you'll need to look for patterns in other dimensions to be able to filter it out. For example, large companies that use bots to navigate the Internet will usually have a unique service provider.

I’ll go into more detail on this below.
Internal traffic
Most users get worried and anxious about spam, which is normal — nobody likes weird URLs showing up in their reports. However, spam isn't the biggest threat to your Google Analytics.
You are!
The traffic generated by people (and bots) working on the site is often overlooked despite the huge negative impact it has. The main reason it's so damaging is that in contrast to spam, internal traffic is difficult to identify once it hits your Analytics, and it can easily get mixed in with your real user data.
There are different types of internal traffic and different ways of dealing with it.
Direct internal traffic
Testers, developers, marketing team, support, outsourcing... the list goes on. Any member of the team that visits the company website or blog for any purpose could be contributing.

In which reports can you look for direct internal traffic?
Unless your company uses a private ISP domain, this traffic is tough to identify once it hits you, and will usually show as Direct in Google Analytics.

Third-party sites/tools
This type of internal traffic includes traffic generated directly by you or your team when using tools to work on the site; for example, management tools like Trello or Asana,
It also considers traffic coming from bots doing automatic work for you; for example, services used to monitor the performance of your site, like Pingdom or GTmetrix.

Some types of tools you should consider:
- Project management
- Social media management
- Performance/uptime monitoring services
- SEO tools
In which reports can you look for internal third-party tools traffic?
This traffic will usually show as Referral in Google Analytics.

Development/staging environments
Some websites use a test environment to make changes before applying them to the main site. Normally, these staging environments have the same tracking code as the production site, so if you don’t filter it out, all the testing will be recorded in Google Analytics.

In which reports can you look for development/staging environments?
This traffic will usually show as Direct in Google Analytics, but you can find it under its own hostname (more on this later).

Web archive sites and cache services
Archive sites like the Wayback Machine offer historical views of websites. The reason you can see those visits on your Analytics — even if they are not hosted on your site — is that the tracking code was installed on your site when the Wayback Machine bot copied your content to its archive.

One thing is for certain: when someone goes to check how your site looked in 2015, they don't have any intention of buying anything from your site — they're simply doing it out of curiosity, so this traffic is not useful.
In which reports can you look for traffic from web archive sites and cache services?
You can also identify this traffic on the hostname report.

A basic understanding of filters
The solutions described below use Google Analytics filters, so to avoid problems and confusion, you'll need some basic understanding of how they work and check some prerequisites.
Things to consider before using filters:
1. Create an unfiltered view.
Before you do anything, it's highly recommendable to make an unfiltered view; it will help you track the efficacy of your filters. Plus, it works as a backup in case something goes wrong.
2. Make sure you have the correct permissions.
You will need edit permissions at the account level to create filters; edit permissions at view or property level won’t work.
3. Filters don’t work retroactively.
In GA, aggregated historical data can’t be deleted, at least not permanently. That's why the sooner you apply the filters to your data, the better.
4. The changes made by filters are permanent!
If your filter is not correctly configured because you didn’t enter the correct expression (missing relevant entries, a typo, an extra space, etc.), you run the risk of losing valuable data FOREVER; there is no way of recovering filtered data.
But don’t worry — if you follow the recommendations below, you shouldn’t have a problem.
5. Wait for it.
Most of the time you can see the effect of the filter within minutes or even seconds after applying it; however, officially it can take up to twenty-four hours, so be patient.
Types of filters
There are two main types of filters: predefined and custom.
Predefined filters are very limited, so I rarely use them. I prefer to use the custom ones because they allow regular expressions, which makes them a lot more flexible.
Within the custom filters, there are five types: exclude, include, lowercase/uppercase, search and replace, and advanced.

Here we will use the first two: exclude and include. We'll save the rest for another occasion.
Essentials of regular expressions
If you already know how to work with regular expressions, you can jump to the next section.
REGEX (short for regular expressions) are text strings prepared to match patterns with the use of some special characters. These characters help match multiple entries in a single filter.
Don’t worry if you don’t know anything about them. We will use only the basics, and for some filters, you will just have to COPY-PASTE the expressions I pre-built.
REGEX special characters
There are many special characters in REGEX, but for basic GA expressions we can focus on three:
- ^ The caret: used to indicate the beginning of a pattern,
- $ The dollar sign: used to indicate the end of a pattern,
- | The pipe or bar: means "OR," and it is used to indicate that you are starting a new pattern.

When using the pipe character, you should never ever:
- Put it at the beginning of the expression,
- Put it at the end of the expression,
- Put 2 or more together.
Any of those will mess up your filter and probably your Analytics.
A simple example of REGEX usage
Let's say I go to a restaurant that has an automatic machine that makes fruit salad, and to choose the fruit, you should use regular xxpressions.
This super machine has the following fruits to choose from: strawberry, orange, blueberry, apple, pineapple, and watermelon.

To make a salad with my favorite fruits (strawberry, blueberry, apple, and watermelon), I have to create a REGEX that matches all of them. Easy! Since the pipe character “|” means OR I could do this:
- REGEX 1: strawberry|blueberry|apple|watermelon

The problem with that expression is that REGEX also considers partial matches, and since pineapple also contains “apple,” it would be selected as well... and I don’t like pineapple!
To avoid that, I can use the other two special characters I mentioned before to make an exact match for apple. The caret “^” (begins here) and the dollar sign “$” (ends here). It will look like this:
- REGEX 2: strawberry|blueberry|^apple$|watermelon

The expression will select precisely the fruits I want.
But let’s say for demonstration's sake that the fewer characters you use, the cheaper the salad will be. To optimize the expression, I can use the ability for partial matches in REGEX.
Since strawberry and blueberry both contain "berry," and no other fruit in the list does, I can rewrite my expression like this:
- Optimized REGEX: berry|^apple$|watermelon

That’s it — now I can get my fruit salad with the right ingredients, and at a lower price.
3 ways of testing your filter expression
As I mentioned before, filter changes are permanent, so you have to make sure your filters and REGEX are correct. There are 3 ways of testing them:
- Right from the filter window; just click on “Verify this filter,” quick and easy. However, it's not the most accurate since it only takes a small sample of data.

- Using an online REGEX tester; very accurate and colorful, you can also learn a lot from these, since they show you exactly the matching parts and give you a brief explanation of why.

- Using an in-table temporary filter in GA; you can test your filter against all your historical data. This is the most precise way of making sure you don’t miss anything.

If you're doing a simple filter or you have plenty of experience, you can use the built-in filter verification. However, if you want to be 100% sure that your REGEX is ok, I recommend you build the expression on the online tester and then recheck it using an in-table filter.
Quick REGEX challenge
Here's a small exercise to get you started. Go to this premade example with the optimized expression from the fruit salad case and test the first 2 REGEX I made. You'll see live how the expressions impact the list.
Now make your own expression to pay as little as possible for the salad.
Remember:
- We only want strawberry, blueberry, apple, and watermelon;
- The fewer characters you use, the less you pay;
- You can do small partial matches, as long as they don’t include the forbidden fruits.
Tip: You can do it with as few as 6 characters.
Now that you know the basics of REGEX, we can continue with the filters below. But I encourage you to put “learn more about REGEX” on your to-do list — they can be incredibly useful not only for GA, but for many tools that allow them.
How to create filters to stop spam, bots, and internal traffic in Google Analytics
Back to our main event: the filters!
Where to start: To avoid being repetitive when describing the filters below, here are the standard steps you need to follow to create them:
- Go to the admin section in your Google Analytics (the gear icon at the bottom left corner),
- Under the View column (master view), click the button “Filters” (don’t click on “All filters“ in the Account column):
- Click the red button “+Add Filter” (if you don’t see it or you can only apply/remove already created filters, then you don’t have edit permissions at the account level. Ask your admin to create them or give you the permissions.):
- Then follow the specific configuration for each of the filters below.


The filter window is your best partner for improving the quality of your Analytics data, so it will be a good idea to get familiar with it.
Valid hostname filter (ghost spam, dev environments)
Prevents traffic from:
- Ghost spam
- Development hostnames
- Scraping sites
- Cache and archive sites
This filter may be the single most effective solution against spam. In contrast with other commonly shared solutions, the hostname filter is preventative, and it rarely needs to be updated.
Ghost spam earns its name because it never really visits your site. It’s sent directly to the Google Analytics servers using a feature called Measurement Protocol, a tool that under normal circumstances allows tracking from devices that you wouldn’t imagine that could be traced, like coffee machines or refrigerators.

Real users pass through your server, then the data is sent to GA; hence it leaves valid information. Ghost spam is sent directly to GA servers, without knowing your site URL; therefore all data left is fake. Source: carloseo.com
The spammer abuses this feature to simulate visits to your site, most likely using automated scripts to send traffic to randomly generated tracking codes (UA-0000000-1).
Since these hits are random, the spammers don't know who they're hitting; for that reason ghost spam will always leave a fake or (not set) host. Using that logic, by creating a filter that only includes valid hostnames all ghost spam will be left out.
Where to find your hostnames
Now here comes the “tricky” part. To create this filter, you will need, to make a list of your valid hostnames.
A list of what!?
Essentially, a hostname is any place where your GA tracking code is present. You can get this information from the hostname report:
- Go to Audience > Select Network > At the top of the table change the primary dimension to Hostname.
If your Analytics is active, you should see at least one: your domain name. If you see more, scan through them and make a list of all the ones that are valid for you.
Types of hostname you can find
The good ones:
|
Type |
Example |
|---|---|
|
Your domain and subdomains |
yourdomain.com |
|
Tools connected to your Analytics |
YouTube, MailChimp |
|
Payment gateways |
Shopify, booking systems |
|
Translation services |
Google Translate |
|
Mobile speed-up services |
Google weblight |
The bad ones (by bad, I mean not useful for your reports):
|
Type |
Example/Description |
|---|---|
|
Staging/development environments |
staging.yourdomain.com |
|
Internet archive sites |
web.archive.org |
|
Scraping sites that don’t bother to trim the content |
The URL of the scraper |
|
Spam |
Most of the time they will show their URL, but sometimes they may use the name of a known website to try to fool you. If you see a URL that you don’t recognize, just think, “do I manage it?” If the answer is no, then it isn't your hostname. |
|
(not set) hostname |
It usually comes from spam. On rare occasions it's related to tracking code issues. |
Below is an example of my hostname report. From the unfiltered view, of course, the master view is squeaky clean.

Now with the list of your good hostnames, make a regular expression. If you only have your domain, then that is your expression; if you have more, create an expression with all of them as we did in the fruit salad example:
Hostname REGEX (example)
yourdomain.com|hostname2|hostname3|hostname4
Important! You cannot create more than one “Include hostname filter”; if you do, you will exclude all data. So try to fit all your hostnames into one expression (you have 255 characters).
The “valid hostname filter” configuration:
- Filter Name: Include valid hostnames
- Filter Type: Custom > Include
- Filter Field: Hostname
- Filter Pattern: [hostname REGEX you created]

Campaign source filter (Crawler spam, internal sources)
Prevents traffic from:
- Crawler spam
- Internal third-party tools (Trello, Asana, Pingdom)
Important note: Even if these hits are shown as a referral, the field you should use in the filter is “Campaign source” — the field “Referral” won’t work.
Filter for crawler spam
The second most common type of spam is crawler. They also pretend to be a valid visit by leaving a fake source URL, but in contrast with ghost spam, these do access your site. Therefore, they leave a correct hostname.
You will need to create an expression the same way as the hostname filter, but this time, you will put together the source/URLs of the spammy traffic. The difference is that you can create multiple exclude filters.
Crawler REGEX (example)
spam1|spam2|spam3|spam4
Crawler REGEX (pre-built)
As I promised, here are latest pre-built crawler expressions that you just need to copy/paste.

The “crawler spam filter” configuration:
- Filter Name: Exclude crawler spam 1
- Filter Type: Custom > Exclude
- Filter Field: Campaign source
- Filter Pattern: [crawler REGEX]

Filter for internal third-party tools
Although you can combine your crawler spam filter with internal third-party tools, I like to have them separated, to keep them organized and more accessible for updates.
The “internal tools filter” configuration:
- Filter Name: Exclude internal tool sources
- Filter Pattern: [tool source REGEX]
Internal Tools REGEX (example)
trello|asana|redmine

In case, that one of the tools that you use internally also sends you traffic from real visitors, don’t filter it. Instead, use the “Exclude Internal URL Query” below.
For example, I use Trello, but since I share analytics guides on my site, some people link them from their Trello accounts.
Filters for language spam and other types of spam
The previous two filters will stop most of the spam; however, some spammers use different methods to bypass the previous solutions.
For example, they try to confuse you by showing one of your valid hostnames combined with a well-known source like Apple, Google, or Moz. Even my site has been a target (not saying that everyone knows my site; it just looks like the spammers don’t agree with my guides).
However, even if the source and host look fine, the spammer injects their message in another part of your reports like the keyword, page title, and even as a language.

In those cases, you will have to take the dimension/report where you find the spam and choose that name in the filter. It's important to consider that the name of the report doesn't always match the name in the filter field:
|
Report name |
Filter field |
|---|---|
|
Language |
Language settings |
|
Referral |
Campaign source |
|
Organic Keyword |
Search term |
|
Service Provider |
ISP Organization |
|
Network Domain |
ISP Domain |
Here are a couple of examples.
The “language spam/bot filter” configuration:
- Filter Name: Exclude language spam
- Filter Type: Custom > Exclude
- Filter Field: Language settings
- Filter Pattern: [Language REGEX]
Language Spam REGEX (Prebuilt)
\s[^\s]*\s|.{15,}|\.|,|^c$

The expression above excludes fake languages that don't meet the required format. For example, take these weird messages appearing instead of regular languages like en-us or es-es:

Examples of language spam
The organic/keyword spam filter configuration:
- Filter Name: Exclude organic spam
- Filter Type: Custom > Exclude
- Filter Field: Search term
- Filter Pattern: [keyword REGEX]

Filters for direct bot traffic
Bot traffic is a little trickier to filter because it doesn't leave a source like spam, but it can still be filtered with a bit of patience.
The first thing you should do is enable bot filtering. In my opinion, it should be enabled by default.
Go to the Admin section of your Analytics and click on View Settings. You will find the option “Exclude all hits from known bots and spiders” below the currency selector:

It would be wonderful if this would take care of every bot — a dream come true. However, there's a catch: the key here is the word “known.” This option only takes care of known bots included in the “IAB known bots and spiders list." That's a good start, but far from enough.
There are a lot of “unknown” bots out there that are not included in that list, so you'll have to play detective and search for patterns of direct bot traffic through different reports until you find something that can be safely filtered without risking your real user data.

To start your bot trail search, click on the Segment box at the top of any report, and select the “Direct traffic” segment.

Then navigate through different reports to see if you find anything suspicious.
Some reports to start with:
- Service provider
- Browser version
- Network domain
- Screen resolution
- Flash version
- Country/City
Signs of bot traffic
Although bots are hard to detect, there are some signals you can follow:
- An unnatural increase of direct traffic
- Old versions (browsers, OS, Flash)
- They visit the home page only (usually represented by a slash “/” in GA)
- Extreme metrics:
- Bounce rate close to 100%,
- Session time close to 0 seconds,
- 1 page per session,
- 100% new users.
Important! If you find traffic that checks off many of these signals, it is likely bot traffic. However, not all entries with these characteristics are bots, and not all bots match these patterns, so be cautious.
Perhaps the most useful report that has helped me identify bot traffic is the “Service Provider” report. Large corporations frequently use their own Internet service provider name.
I also have a pre-built expression for ISP bots, similar to the crawler expressions.
The bot ISP filter configuration:
- Filter Name: Exclude bots by ISP
- Filter Type: Custom > Exclude
- Filter Field: ISP organization
- Filter Pattern: [ISP provider REGEX]
ISP provider bots REGEX (prebuilt)
hubspot|^google\sllc$|^google\sinc\.$|alibaba\.com\sllc|ovh\shosting\sinc\.
Latest ISP bot expression

IP filter for internal traffic
We already covered different types of internal traffic, the one from test sites (with the hostname filter), and the one from third-party tools (with the campaign source filter).
Now it's time to look at the most common and damaging of all: the traffic generated directly by you or any member of your team while working on any task for the site.
To deal with this, the standard solution is to create a filter that excludes the public IP (not private) of all locations used to work on the site.
Examples of places/people that should be filtered
- Office
- Support
- Home
- Developers
- Hotel
- Coffee shop
- Bar
- Mall
- Any place that is regularly used to work on your site
To find the public IP of the location you are working at, simply search for "my IP" in Google. You will see one of these versions:
|
IP version |
Example |
|---|---|
|
Short IPv4 |
1.23.45.678 |
|
Long IPv6 |
2001:0db8:85a3:0000:0000:8a2e:0370:7334 |
No matter which version you see, make a list with the IP of each place and put them together with a REGEX, the same way we did with other filters.
- IP address expression: IP1|IP2|IP3|IP4 and so on.
The static IP filter configuration:
- Filter Name: Exclude internal traffic (IP)
- Filter Type: Custom > Exclude
- Filter Field: IP Address
- Filter Pattern: [The IP expression]
Cases when this filter won’t be optimal:
There are some cases in which the IP filter won’t be as efficient as it used to be:
- You use IP anonymization (required by the GDPR regulation). When you anonymize the IP in GA, the last part of the IP is changed to 0. This means that if you have 1.23.45.678, GA will pass it as 1.23.45.0, so you need to put it like that in your filter. The problem is that you might be excluding other IPs that are not yours.
- Your Internet provider changes your IP frequently (Dynamic IP). This has become a common issue lately, especially if you have the long version (IPv6).
- Your team works from multiple locations. The way of working is changing — now, not all companies operate from a central office. It's often the case that some will work from home, others from the train, in a coffee shop, etc. You can still filter those places; however, maintaining the list of IPs to exclude can be a nightmare,
- You or your team travel frequently. Similar to the previous scenario, if you or your team travels constantly, there's no way you can keep up with the IP filters.
If you check one or more of these scenarios, then this filter is not optimal for you; I recommend you to try the “Advanced internal URL query filter” below.
URL query filter for internal traffic
If there are dozens or hundreds of employees in the company, it's extremely difficult to exclude them when they're traveling, accessing the site from their personal locations, or mobile networks.
Here’s where the URL query comes to the rescue. To use this filter you just need to add a query parameter. I add “?internal" to any link your team uses to access your site:
- Internal newsletters
- Management tools (Trello, Redmine)
- Emails to colleagues
- Also works by directly adding it in the browser address bar
Basic internal URL query filter
The basic version of this solution is to create a filter to exclude any URL that contains the query “?internal”.
- Filter Name: Exclude Internal Traffic (URL Query)
- Filter Type: Custom > Exclude
- Filter Field: Request URI
- Filter Pattern: \?internal

This solution is perfect for instances were the user will most likely stay on the landing page, for example, when sending a newsletter to all employees to check a new post.

If the user will likely visit more than the landing page, then the subsequent pages will be recorded.
Advanced internal URL query filter
This solution is the champion of all internal traffic filters!
It’s a more comprehensive version of the previous solution and works by filtering internal traffic dynamically using Google Tag Manager, a GA custom dimension, and cookies.

Although this solution is a bit more complicated to set up, once it's in place:
- It doesn’t need maintenance
- Any team member can use it, no need to explain techy stuff
- Can be used from any location
- Can be used from any device, and any browser
To activate the filter, you just have to add the text “?internal” to any URL of the website.

That will insert a small cookie in the browser that will tell GA not to record the visits from that browser.
And the best of it is that the cookie will stay there for a year (unless it is manually removed), so the user doesn’t have to add “?internal” every time.
Bonus filter: Include only internal traffic
In some occasions, it's interesting to know the traffic generated internally by employees — maybe because you want to measure the success of an internal campaign or just because you're a curious person.
In that case, you should create an additional view, call it “Internal Traffic Only,” and use one of the internal filters above. Just one! Because if you have multiple include filters, the hit will need to match all of them to be counted.
If you configured the “Advanced internal URL query” filter, use that one. If not, choose one of the others.
The configuration is exactly the same — you only need to change “Exclude” for “Include.”

Cleaning historical data
The filters will prevent future hits from junk traffic.
But what about past affected data?
I know I told you that deleting aggregated historical data is not possible in GA. However, there's still a way to temporarily clean up at least some of the nasty traffic that has already polluted your reports.
For this, we'll use an advanced segment (a subset of your Analytics data). There are built-in segments like “Organic” or “Mobile,” but you can also build one using your own set of rules.
To clean our historical data, we will build a segment using all the expressions from the filters above as conditions (except the ones from the IP filter, because IPs are not stored in GA; hence, they can’t be segmented).
To help you get started, you can import this segment template.
You just need to follow the instructions on that page and replace the placeholders. Here is how it looks:

In the actual template, all text is black; the colors are just to help you visualize the conditions.
After importing it, to select the segment:
- Click on the box that says “All users” at the top of any of your reports
- From your list of segments, check the one that says “0. All Users - Clean”
- Lastly, uncheck the “All Users”

Now you can navigate through your reaports and all the junk traffic included in the segment will be removed.
A few things to consider when using this segment:
- Segments have to be selected each time. A way of having it selected by default is by adding a bookmark when the segment is selected.
- You can remove or add conditions if you need to.
- You can edit the segment at any time to update it or add conditions (open the list of segments, then click “Actions” then “Edit”).

- The hostname expression and third-party tools expression are different for each site.
- If your site has a large volume of traffic, segments may sample your data when selected, so if you see the little shield icon at the top of your reports go yellow (normally is green), try choosing a shorter period (i.e. 1 year, 6 months, one month).

Conclusion: Which cake would you eat?
Having real and accurate data is essential for your Google Analytics to report as you would expect.
But if you haven’t filtered it properly, it’s almost certain that it will be filled with all sorts of junk and artificial information.
And the worst part is that if don't realize that your reports contain bogus data, you will likely make wrong or poor decisions when deciding on the next steps for your site or business.

The filters I share above will help you prevent the three most harmful threats that are polluting your Google Analytics and don’t let you get a clear view of the actual performance of your site: spam, bots, and internal traffic.
Once these filters are in place, you can rest assured that your efforts (and money!) won’t be wasted on analyzing deceptive Google Analytics data, and your decisions will be based on solid information.
And the benefits don’t stop there. If you're using other tools that import data from GA, for example, WordPress plugins like GADWP, excel add-ins like AnalyticsEdge, or SEO suites like Moz Pro, the benefits will trickle down to all of them as well.

Besides highlighting the importance of the filters in GA (which I hope I made clear by now), I would also love that for the preparation of these filters to give you the curiosity and basis to create others that will allow you to do all sorts of remarkable things with your data.
Remember, filters not only allow you to keep away junk, you can also use them to rearrange your real user information — but more on that on another occasion.
That’s it! I hope these tips help you make more sense of your data and make accurate decisions.
Have any questions, feedback, experiences? Let me know in the comments, or reach me on Twitter @carlosesal.
Complementary resources:
- Google Analytics spam & bots (FAQ): Common data quality questions and concerns answered
- Ultimate guide to stopping bots and Google Analytics spam (Always up to date)
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!